在當前數位時代中,資料庫查詢已成為許多行業的核心任務,然而對於不具備 SQL 語法知識的人來說,查詢資料庫仍是一大挑戰。隨著生成式 AI 模型的進步,語言模型不僅在自然語言處理領域取得顯著成就,更展現了其在自然語言到 SQL 查詢轉換(Text-to-SQL)任務中的潛力。將複雜的資料庫查詢簡化為自然語言輸入,進一步拉近了專業技術和非技術用戶之間的鴻溝。
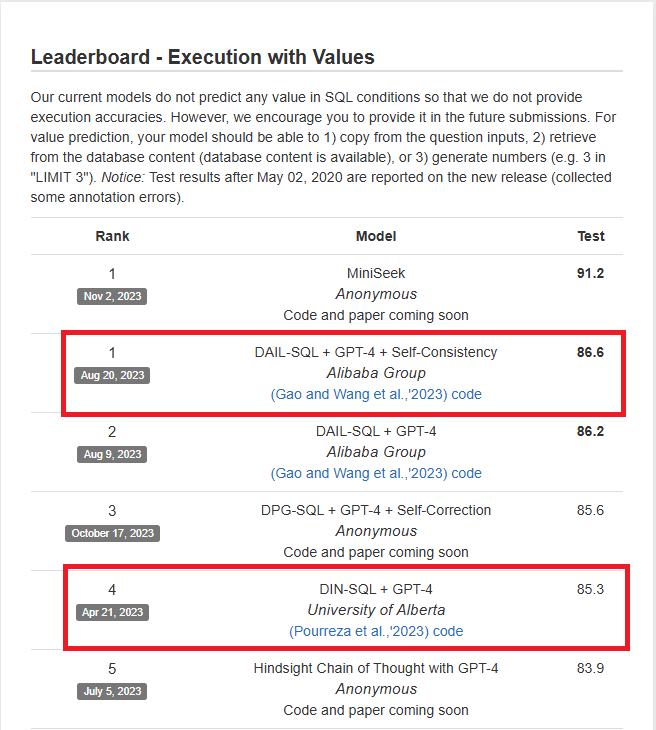
昨天我們介紹了 DIN-SQL 如何改進 LLM Text-to-SQL 的方法,解決了欄位名稱語意理解困難、 SQL 困難語法錯誤、幻覺等問題,雖然已經能解決掉大部分的問題,但再 LLM 生成方面還是會受限於機率模型的原因,導致生成錯誤。今天將透過此論文一起來發現 LLM 偏好的 Prompt Template 吧。
前面我們先介紹了基本的 Text-to-SQL 方法,簡實應用上我們不可能只針對單一表格查詢,經常會使用到多表 JOIN、GROUP BY、Subquery等進階方法,因此我們需要更深入探討解決方法。本篇將會透過兩篇 Text-to-SQL 競賽前幾名的論文來探討 Prompt Engineering 的方法。
Basic Prompt(BS𝑝):
基本的 Prompt 格式。
Text Representation Prompt(TR𝑝):
相較於BS Prompt 在起始位置增加 instruction 。
OpenAI Demostration Prompt(OD𝑝):
這是OpenAI官方範例,特色是會在前面加上#字號,並在上方增加指令"Complete sqlite SQL query only and with no expla nation"。
Code Representation Prompt(CR𝑝):
以DDL格式包裝成Prompt,並且能在CODE-DAVINCI-002模型上達到75.6%的準確度。
Alpaca SFT Prompt(AS𝑝):
以Llama格式設計成Alpaca SFT Prompt,用於後續supervised fine-tuning。
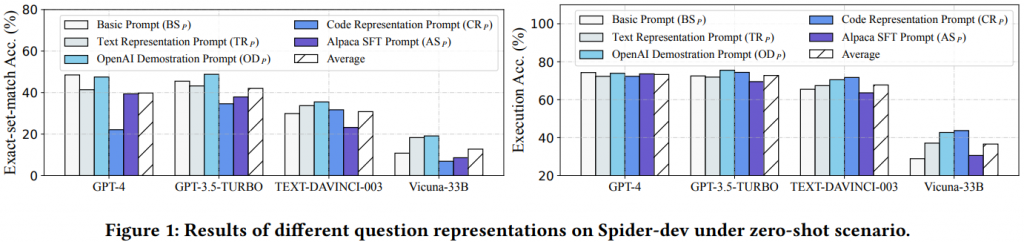
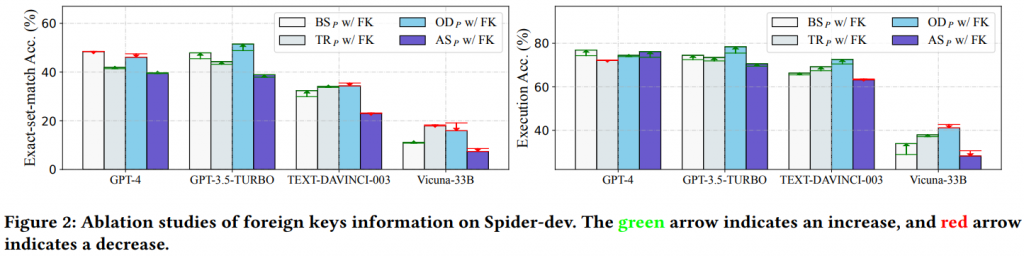
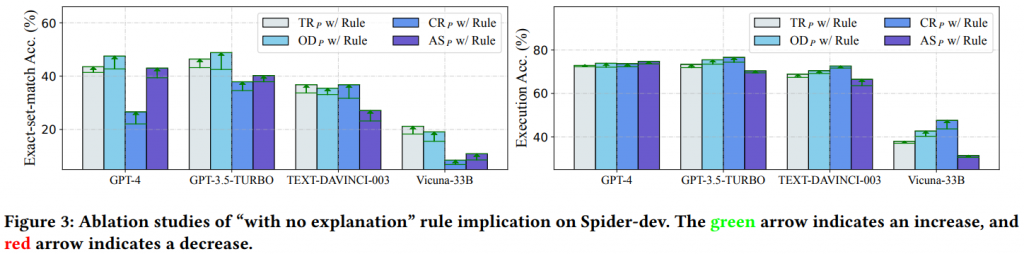
透過上圖可以發現 OD𝑝 的綜合水平最好,而 GPT-3.5-TURBO 使用 OD𝑝 可以達到 75.5% 的執行準確率,能用極低的成本實現跟 GPT-4 差不多的水平。出乎意料的是 GPT-4 在具有 FK 的任務上偏好簡單的 BS𝑝 方法,但整體來說還是使用 OD𝑝 的 Prompt 較符合整體效益。也能看出目前開源模型還是跟雲端模型有一定差距。
【In-Context Learning for Text-to-SQL】
論文中也使用了一種 Similarity Selection Context 概念用於提示 LLM 如何生成正確的 SQL 語法,方法大致可分為以下四種:
Random:
顧名思義為隨機抽取k個範例加入Prompt。
Question Similarity Selection:
透過 pre-trained language model 針對「Question」去尋找最相似的範例,常見有 Embedding, KNN 方法。
Masked Question Similarity Selection:
透過替換 Table name、Column name 和 Value 為 Masked 來消除 Embedding 落入特定領域的影響。
Query Similarity Selection:
先用基礎方法生成出 SQL Query 後再透過 Embedding 等方法找出相似的範例。
【Example Organization】
Full-Information Organization (FI𝑂):
包含Schema一同提供給LLM,缺點浪費大量tokens。
SQL-Only Organization(SO𝑂):
僅提供Query Syntax,缺點是少了Question和Query的相關性,會導致LLM效果變差。
DAIL:

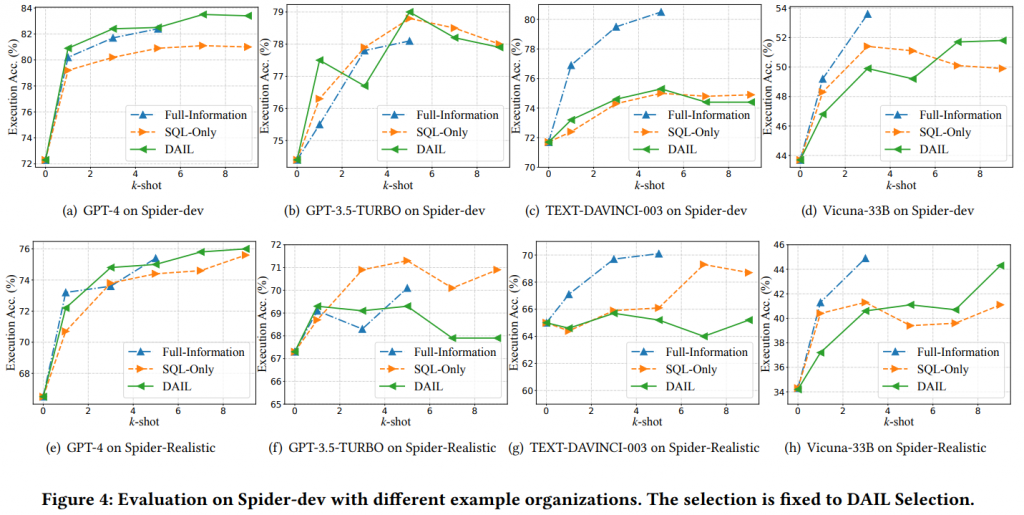
筆者僅挑幾個論文中的重點實驗介紹。筆者幫大家整理了以下 Text-to-SQL 的重點,有些內容可能沒在本文章出現過,有興趣的朋友可以去看原文。
(with no explanation 是指作者發現在 Prompt 中加入此指令模型能有效提升,類似CoT的相反操作。)

